## Summary
Embeddings are used in AI for tasks like search and clustering. Storing embeddings in Postgres with pgvector improves performance but can be challenging at scale. Choosing a model with fewer dimensions can lead to faster queries and better efficiency.
## Highlights
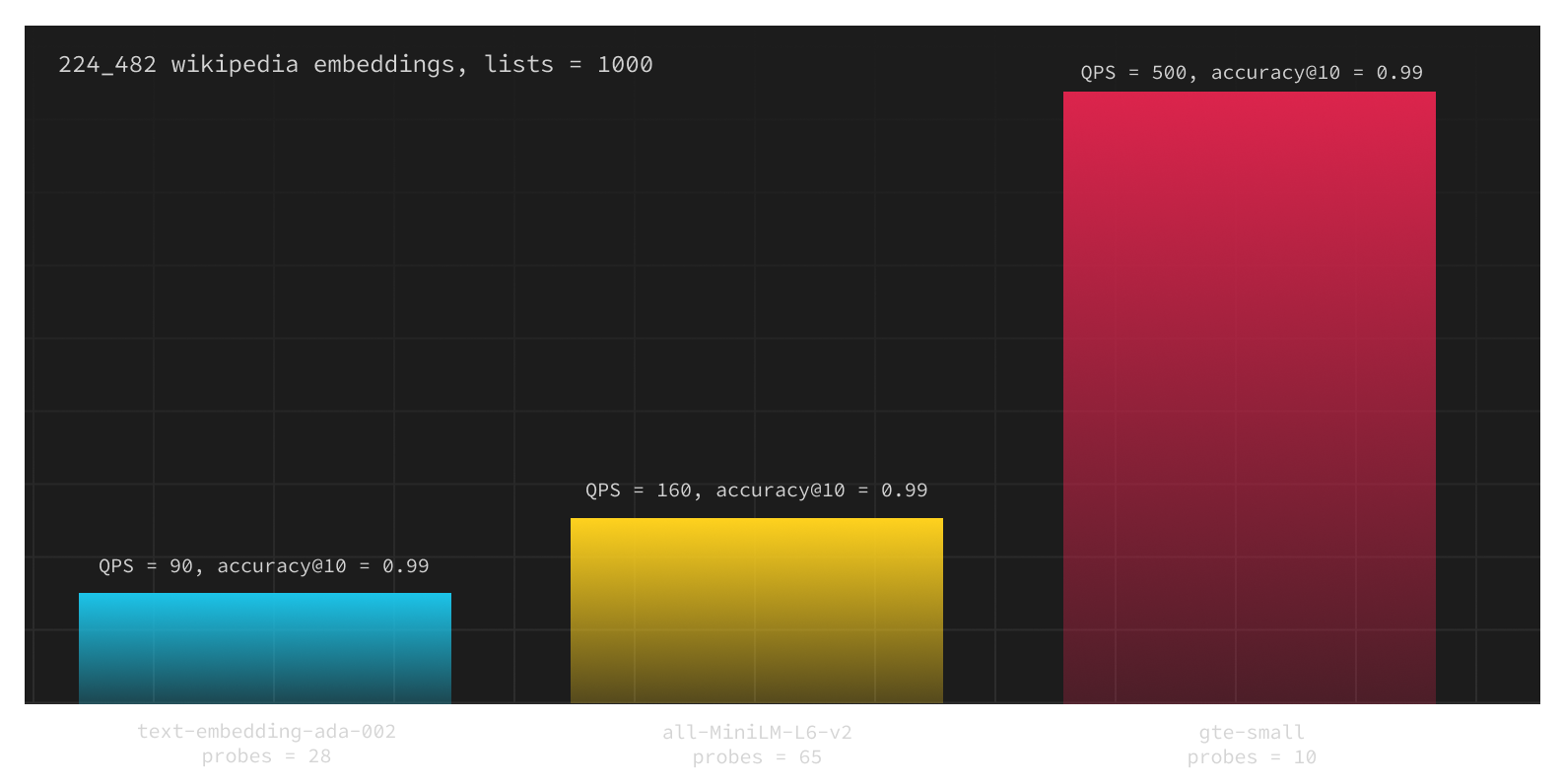
After that, we decided to try the recently published [gte-small](https://huggingface.co/thenlper/gte-small) (also 384 dimensions), and the results were even more astonishing. With `gte-small`, we could set `probes=10` to achieve the same level of `precision@10 = 0.99`. Consequently, we observed more than a 200% improvement in requests per second for pgvector with embeddings generated by `gte-small` compared to `all-MiniLM-L6-v2`.
 ([View Highlight](https://read.readwise.io/read/01j9zdrt457t9xchyq5kk8fc89))
It's worth noting that many models today are trained on English-only text (such as `gte-small` and `all-MiniLM-L6-v2`). If you need to work with other languages, be sure to choose a model that supports them, such as [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small). ([View Highlight](https://read.readwise.io/read/01j9zdsasw7vg0d60y31r1wdft))